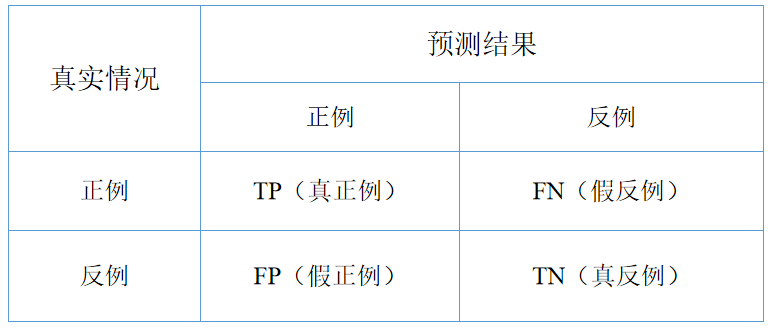
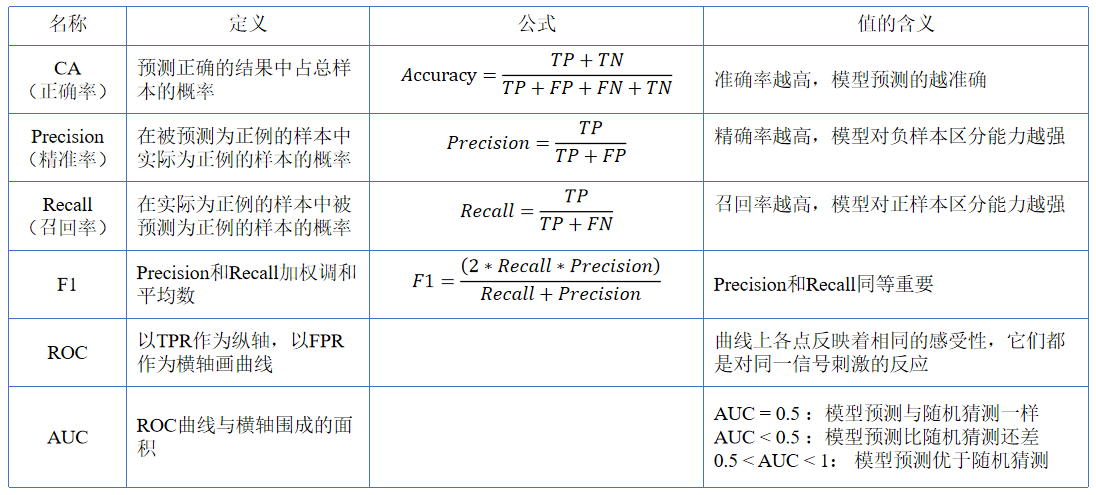
混淆矩阵
显示根据分类器评估结果构造的混淆矩阵。
输入:
评价结果:分类算法测试结果
输出:
选择数据:从混淆矩阵中选择的数据子集
数据:包含是否选择数据实例的附加信息的数据
混淆矩阵组件给出了预测类和实际类之间实例的数量/比例。矩阵中元素的选择将相应的实例提供给输出信号。通过这种方式,可以观察到哪些具体实例被错误分类了,以及如何被错误分类的。
该组件通常从模型评估组件中获得评估结果;模式示例如下所示。
1.当评价结果包含多个学习算法的数据时,我们必须在学习器框中选择一个。快照显示了混淆矩阵树和朴素贝叶斯模型训练和测试鸢尾花数据。组件的右侧包含朴素贝叶斯模型的矩阵(因为该模型是在左侧选择的)。每一行对应一个正确的类,而列表示预测的类。例如,有四种鸢尾花(Iris-versicolor)被错归类为鸢尾花(Iris-virginica)。最右边的一列给出了每个类的实例数(三个类各有50个irises),最下面的一列给出了分类到每个类的实例数(例如,48个实例被分类到virginica)。
2.在展示页面中,我们选择希望在矩阵中看到的数据。
- 实例数以数字方式显示正确和错误分类的实例。
- 预测比例显示了有多少实例被分类,比如鸢尾花-versicolor是真正的类别;在表格中我们可以读到0%的是setosae, 88.5%的分类versicolor是versicolor, 7.7%是virginicae。
- 实际比例显示了相反的关系:在所有真正的versicolors中,92%被归为versicolors, 8%被归为virginicae。
3.在选择中,可以选择所需的输出。
- 点击“选择正确分类”按钮,将通过选择矩阵的对角线,把所有正确分类的实例发送到输出。
- 点击“选择错误分类”按钮,将选择错误分类的实例。
- 点击“重置”按钮,则会取消选择。如前所述,还可以选择表中的单个单元格来选择特定类型的错误分类实例(例如versicolors被分类为virginicae)。
4.在发送所选实例时,该组件可以添加新的属性,比如预测类或它们的概率,需要勾选相应的选项“预测”或“概率”。
5.如果“自动发送”被勾选,则组件会输出每一个更改。如果没有,用户将需要单击“自动发送”提交更改。