
热图

用热图展示属性之间的相关性。
输入:
数据:输入数据集(包括实例的数量和变量的数量)
输出:
所选的数据:在热图中选中的实例(包括实例的数量和变量的数量)
热图组件根据离散或连续属性的值绘制二维双向矩阵可视化图形。热图只适用于数值型数据集。数值的颜色用所选择的渐变色板来填充。通过将两个类变量及其属性值显示在x轴和y轴上,可以看到哪些属性值最强,哪些值最弱,从而可以从中找到每个类的典型特征。
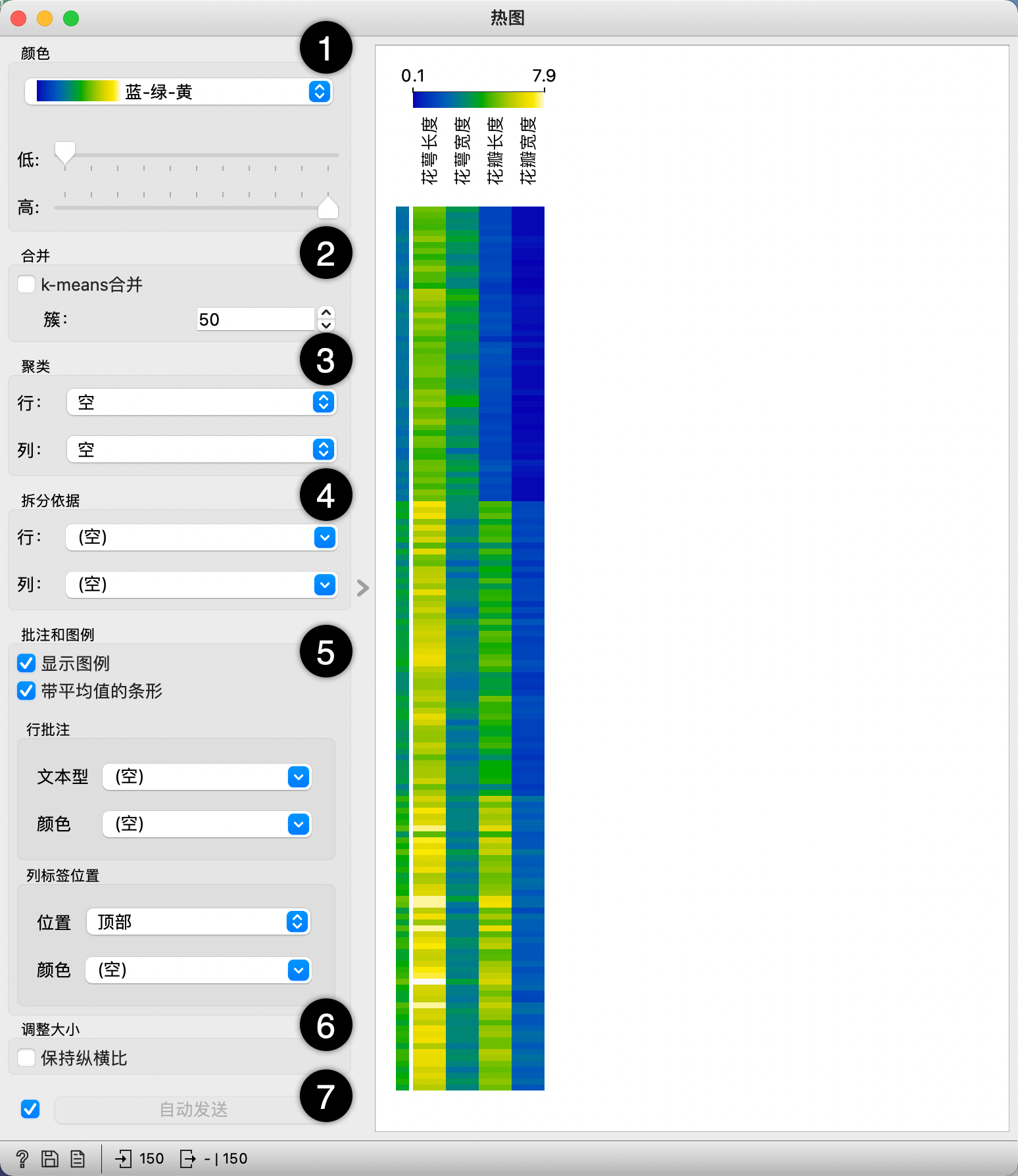
功能:
1.颜色调色板。颜色中的可选类型有线型,发散型,色盲友好型,以及其他。调色板的阈值包括低和高两端,其中,低表示值低的属性,高表示值高的属性。发散型调色板有两种极端颜色和中点的中性颜色(黑色或白色),集中点默认为0,可以根据数据范围进行修改。
2.合并(行)。如果数据实例过多,可用k-means算法进行合并 (默认为50个)。
3.聚类(行或列)。行列的聚类方式,包括空、聚类、聚类(基于最优叶序),其中“空”选项直接显示所选择的数据集的属性和数值行,“聚类”选项使用欧几里德距离计算属性之间的相似性进行分层聚类,“聚类(基于最优叶序)”选项可以使得相邻元素的相似度总和最大化。
4.用分类变量分割行或列。如果数据包含类变量,将自动按类属性分割行。
5.选择在注释和图例中显示的内容。行批注的选项可以是空或者数据集中的任何一个属性。选择列标签位置:在“位置”的可选项中有“空”、“顶部”、“底部”、“顶部和底部”。
6.如果勾选“保持纵横比”,每个值将以正方形的形式展现。
7.如果勾选“自动发送”,更改后将会自动传递。否则,在设置上述参数之后,需要手动点击“发送”。
热图中包括行或列的聚类、行和列注释以及通过分类变量分割数据等功能,这些细小功能使得图表展示更加清晰简洁。其中,热图中的行和列聚类是独立执行的。行聚类是通过欧氏距离计算的,而列聚类是使用皮尔逊相关系数来计算的。
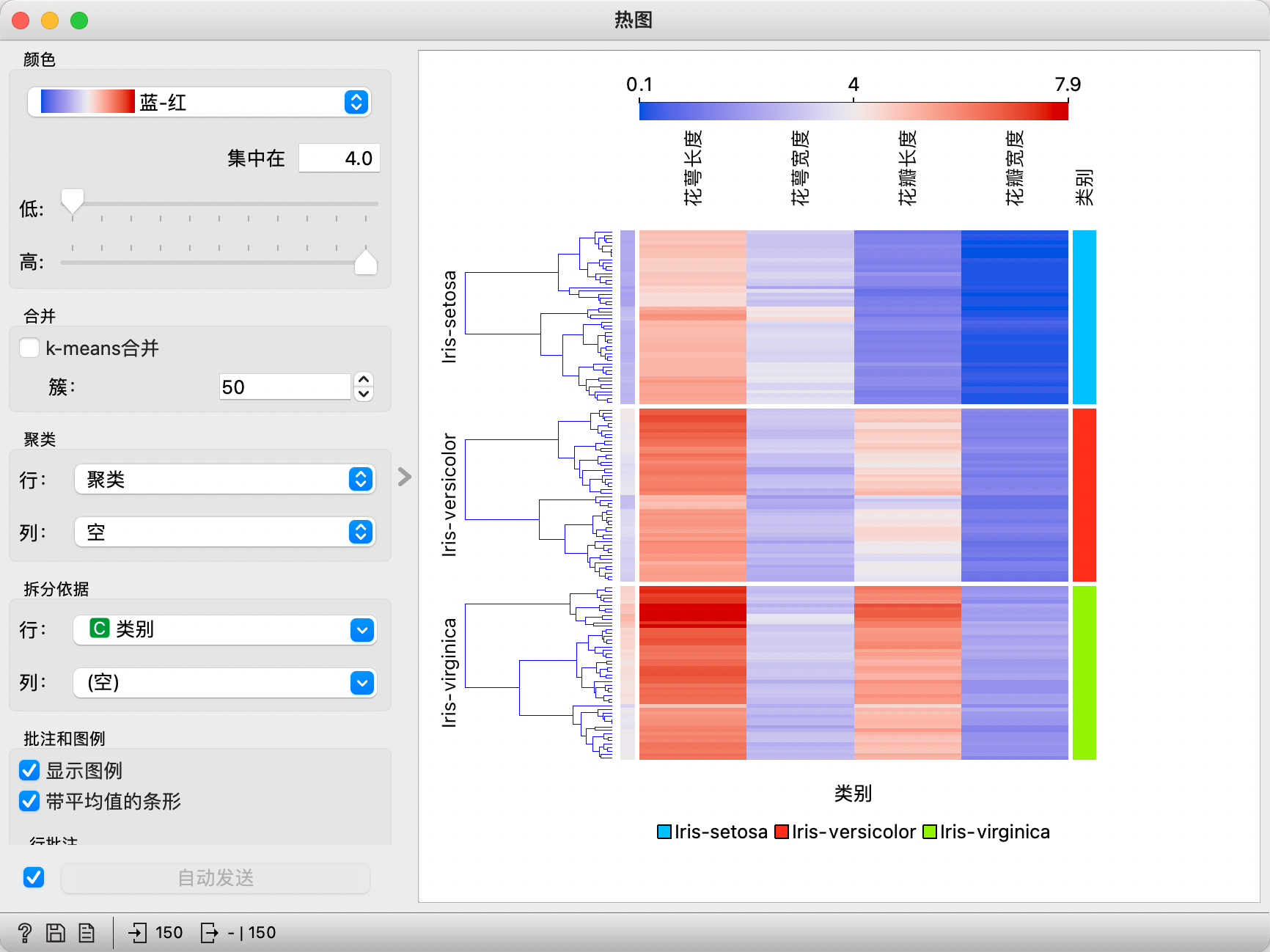
示例:
下面所展示的热图使用的数据集是鸢尾花数据。对鸢尾花的类别进行聚类,可以更加清晰地看到每种类型鸢尾花的花萼长度、花萼宽度、花瓣长度以及花瓣宽度所处的范围。
