
数据透视表

根据列值重新统计数据并形成数据表。
输入:
数据:输入数据集
输出:
透视表:组件中所展示的列联矩阵
过滤数据:从图中选择的子集
分组数据:由行值定义的组的聚合
数据透视表将原始表中的数据总结为一个统计表。统计数据可以包括总和、平均数、计数等。该组件还允许从原始数据表中选择一个子集,并按行值分组,行值必须是一个离散变量。表中不能显示只有数字变量的数据。
功能:
1.行值中的变量类型一般为离散或数值变量。数值变量需要是整数类型。
2.列值中的变量类型一般为离散变量。变量值将以列的形式出现在表中。
3.值中选择用于聚合的变量。聚合的值将作为单元格显示在表中。
4.聚合方法:
----对于任何变量类型:
- Count:具有给定的行和列的实例数。
- 去重复计数:去除重复值的行和列的实例数。
----数值变量:
- 求和:数值的总和。
- 平均值:数值的平均值。
- 众数:子集出现频率最高的值。
- 最小值:子集中数值最小的值。
- 最大值:子集中数值最大的值。
- 中位数:子集中处于中间位置的值。
- 方差:子集的方差。
----对于离散变量:
- 多数:子集最常出现的值。
5.在左边的框中打勾可以自动输出任何更改。否则,需要手动点击。
示例:
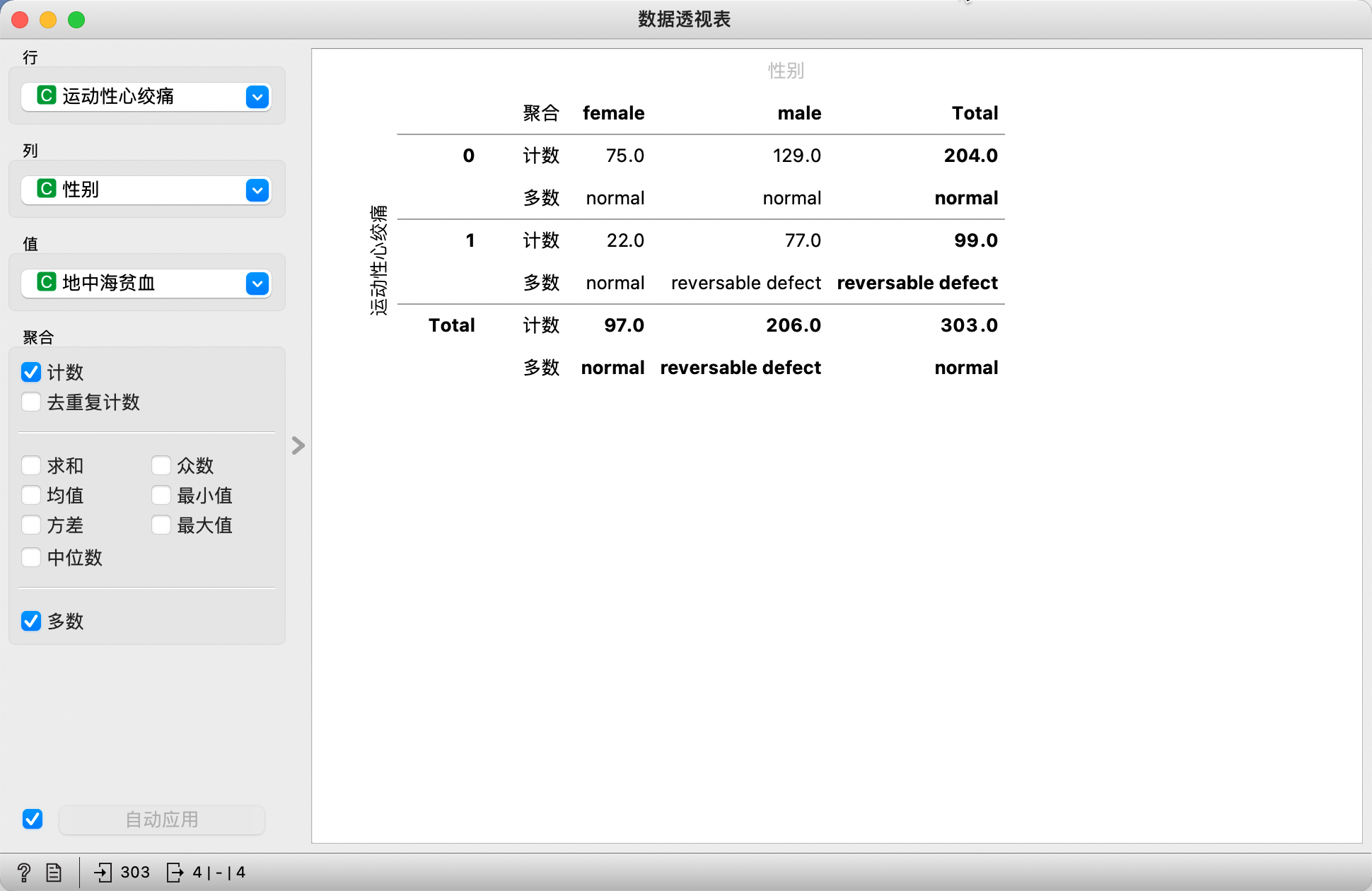
仅选择离散变量的数据透视表的示例。我们在这个例子中使用的是心脏病数据集。在行中选择运动性心绞痛变量,在列中选择性别,在值中选择地中海贫血。
我们选择计数和多数作为聚合方法。在数据透视表中,我们可以看到没有运动性心绞痛且为女性的实例有75个,没有运动性心绞痛且为男性的实例有129个。这些数据仅仅是统计了发生的次数,没有任何其他意义。
第二行结果是多数聚合方法的结果。结果显示,没有患运动性心绞痛的女性其地中海贫血指标也是正常的;相反,患有运动性心绞痛的女性其地中海贫血指标均存在反转效应。
带有数值变量的数据透视表的示例。我们在这个例子中使用的是心脏病数据集。在行中选择运动性心绞痛变量,在列中选择性别,在值中选择静息血压。
我们选择了计数、求和以及中位数作为聚合方法。在计数结果行中,我们看到有75名女性没有患运动性心绞痛,与之前的离散值一样。但在总和与中位数的结果有所不同。我们可以看到没有患运动性心绞痛的女性其静息血压总和为9759,中位数为130。
