关联规则
用来归纳关联规则
输入:
数据:数据集(数据集中实例和变量的数量)
输出:
匹配数据:符合条件的数据实例(根据选择的项目集来确定输出实例和变量的数量)
关联规则组件实现了FP-growth频繁模式挖掘算法和桶式优化,常用于少数项目的条件数据库。在寻找关联规则时,可以选择“仅归纳分类规则”,也可以选择“按以下限制搜索”。
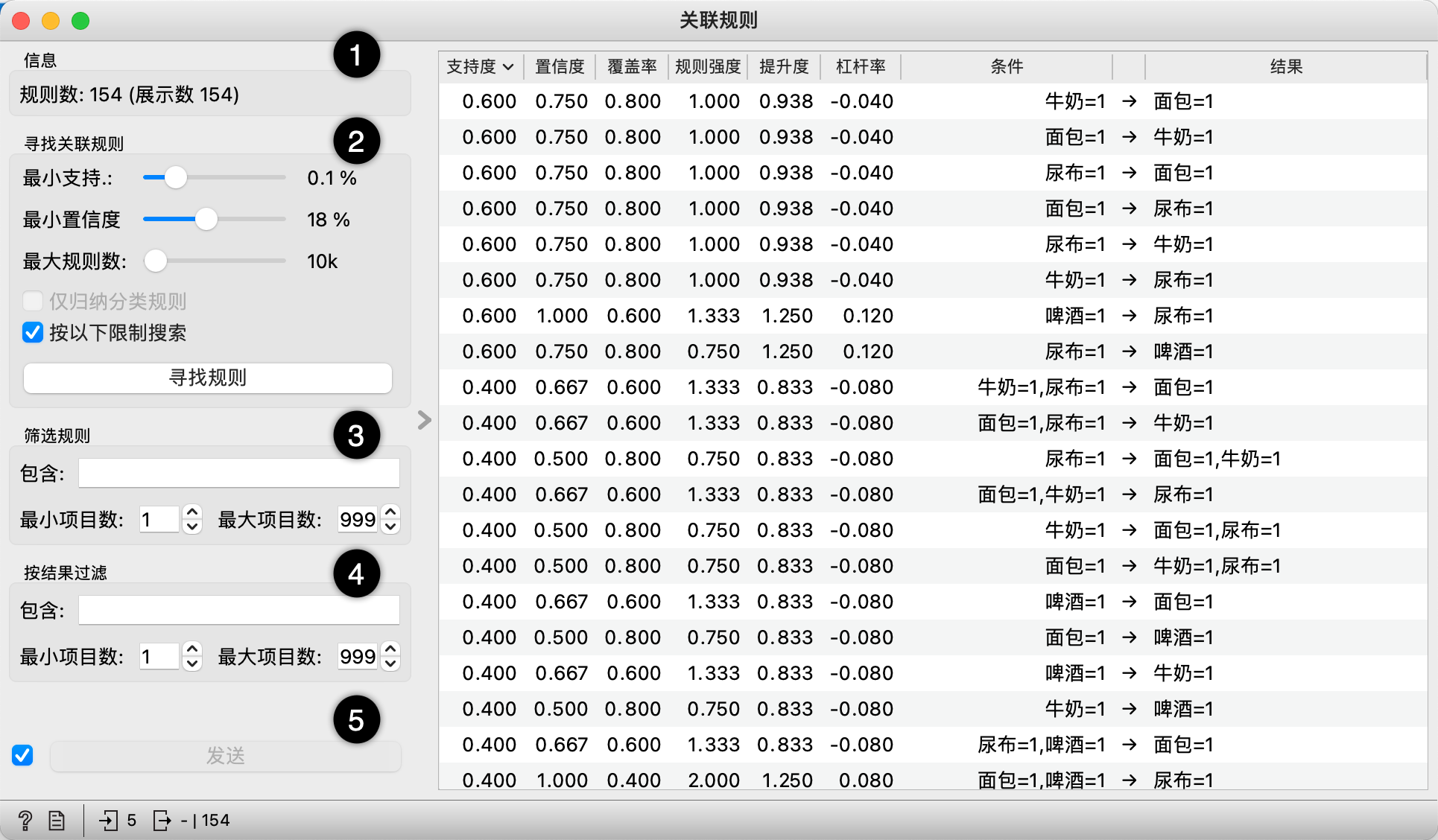
功能:
1.数据集的相关信息。
2.在“寻找关联规则”中,可以设置规则归纳的标准。
- 最小支持:整个规则覆盖的项目数占整个数据集项目数的百分比;
- 最小置信度:符合右边(结果)的例子数在符合左边(条件)的例子数中的比例;
- 最大规则树:用来限制算法生成的规则数量,原因是太多的规则会大大降低组件的运行速度。
如果勾选了“按以下限制搜索”,将会执行“筛选规则”和“按结果过滤”中设置的筛选条件。
3.筛选规则。在“包含”中输入以空格隔开的正则表达式,用于过滤条件中的规则。最小项目数:条件项目集中包含的最小项目数;最大项目数:条件项目集中包含的最大项目数。
4.按结果过滤。在“包含”中输入以空格隔开的正则表达式,用于过滤结果中的规则。最小项目数:结果项目集中包含的最小项目数;最大项目数:结果项目集中包含的最大项目数。
5. 如果勾选了“发送”选项,则自动输出匹配所选关联规则的数据实例;否则,按“Send Selection”选项。
示例:
频繁项集可以直接与其他组件一起使用。