
鸢尾花品种分类预测
在本案例中我们将在蓝鲸数据中进行数据挖掘的分类问题,分类的目的是对鸢尾花的品种进行预测,算法部分选取决策树及神经网络算法构建预测模型,以方便两个模型的性能对比。本案例的整体工作流如图1所示。
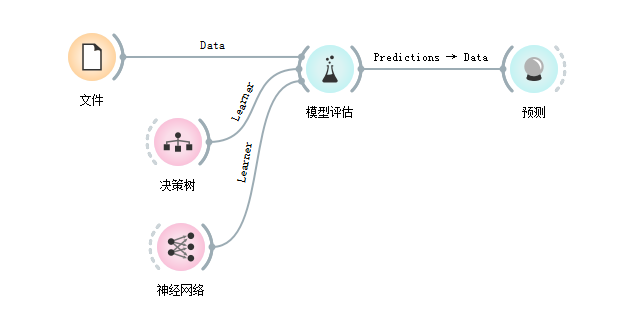
图1
一、案例背景
假设有一名植物学爱好者对她发现的鸢尾花的品种很感兴趣。她收集了每朵鸢尾花的一些测量数据:花瓣的长度和宽度以及花萼的长度和宽度,所有测量结果的单位都是厘米。
她还有一些鸢尾花分类的测量数据,这些花之前已经被植物学专家鉴定为属于setosa、versicolor或virginica三个品种之一。对于这些测量数据,她可以确定每朵鸢尾花所属的品种。
基于这些数据,我们可以构建一个机器学习模型,从这些已知品种的鸢尾花测量数据中进行学习,从而能够预测新鸢尾花的品种。因为我们有已知的鸢尾花的测量数据,是数据挖掘中的分类问题,是一个有监督学习问题。
二、分析过程
1.数据的导入与观测
添加“文件”组件用于加载本地数据,选择蓝鲸已经集成的iris.tab,即鸢尾花数据集,这是机器学习和统计学中一个经典的数据集,“文件”组件也可以显示数据集的基本信息。
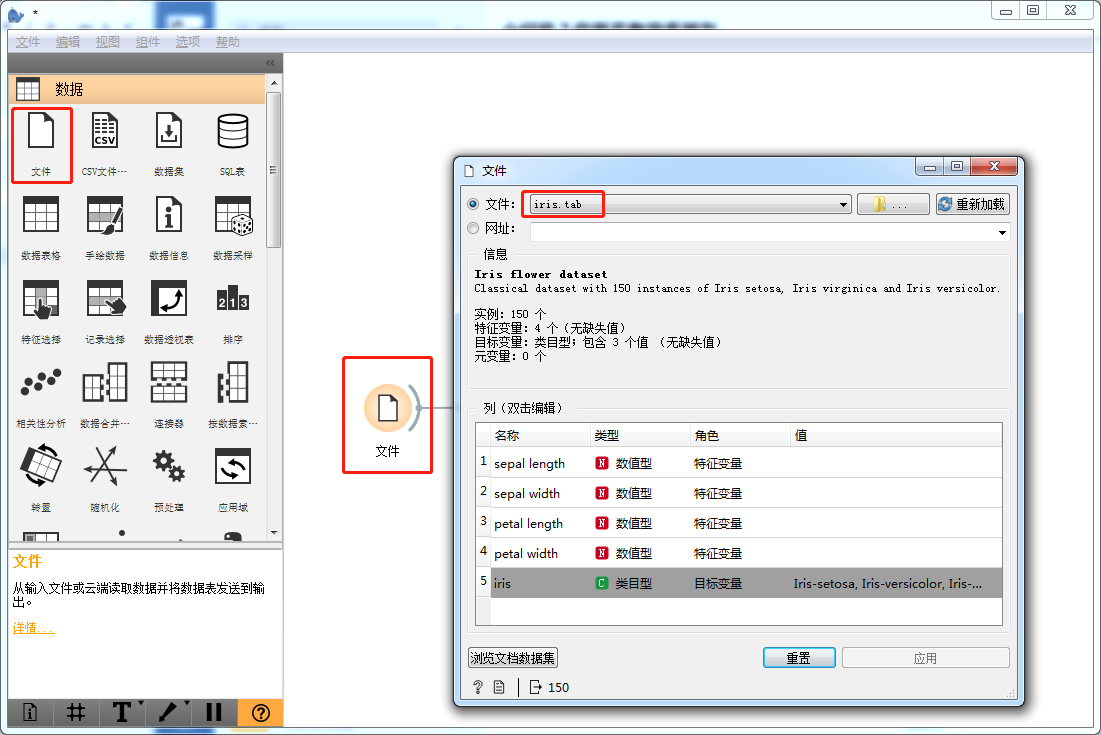
图2
2.算法选择与设置
分类预测属于有监督问题,用户需要定义好目标特征变量,可通过双击组件来实现编辑。算法的参数保持默认设置,如图3所示。
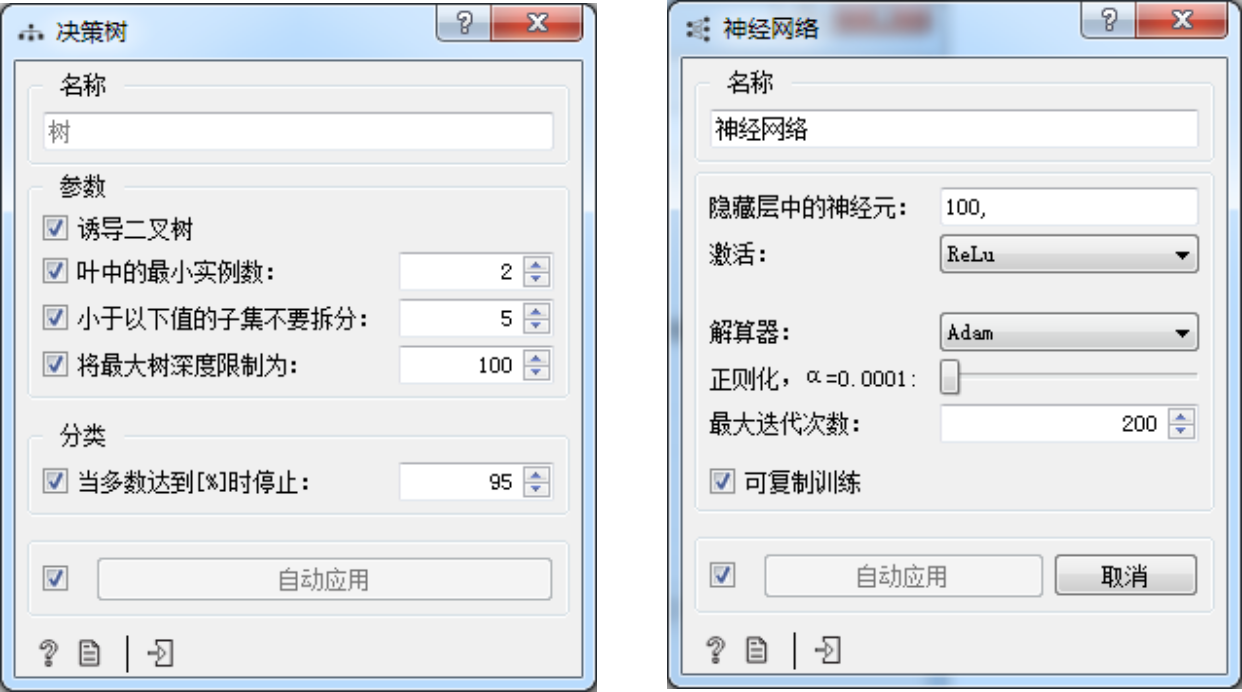
图3
3.模型评估
模型评估组件用于观测训练模型的性能,本实验中由于数据体量较小,可采用“10折交叉检验”进行训练,各训练模型性能参数如图4所示。
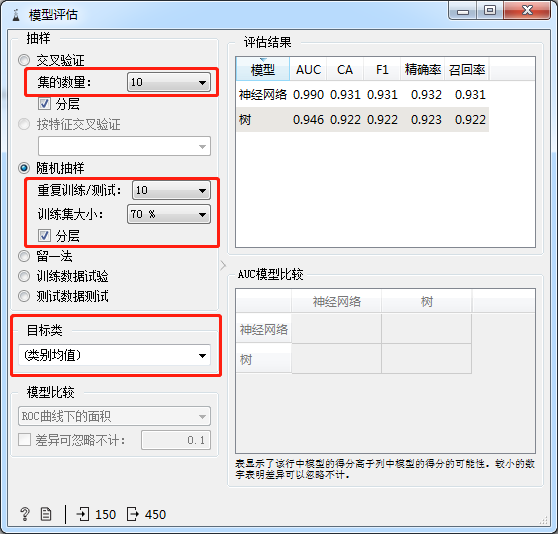
图4
从整体上看,神经网络模型的AUC值稍大于决策树模型,具有较强的泛化性能;然而神经网络模型的准确度(CA)、调和平均值(F1)、精度(Precision)皆弱于决策树模型,决策树模型具有较高的预测精度。
4.预测与评估
最后,通过“预测”组件观察两种不同模型的预测拟合值与真实值的分布情况,如图5所示,基于决策树模型的预测值,相对神经网络模型的预测值而言,精度相对较高。
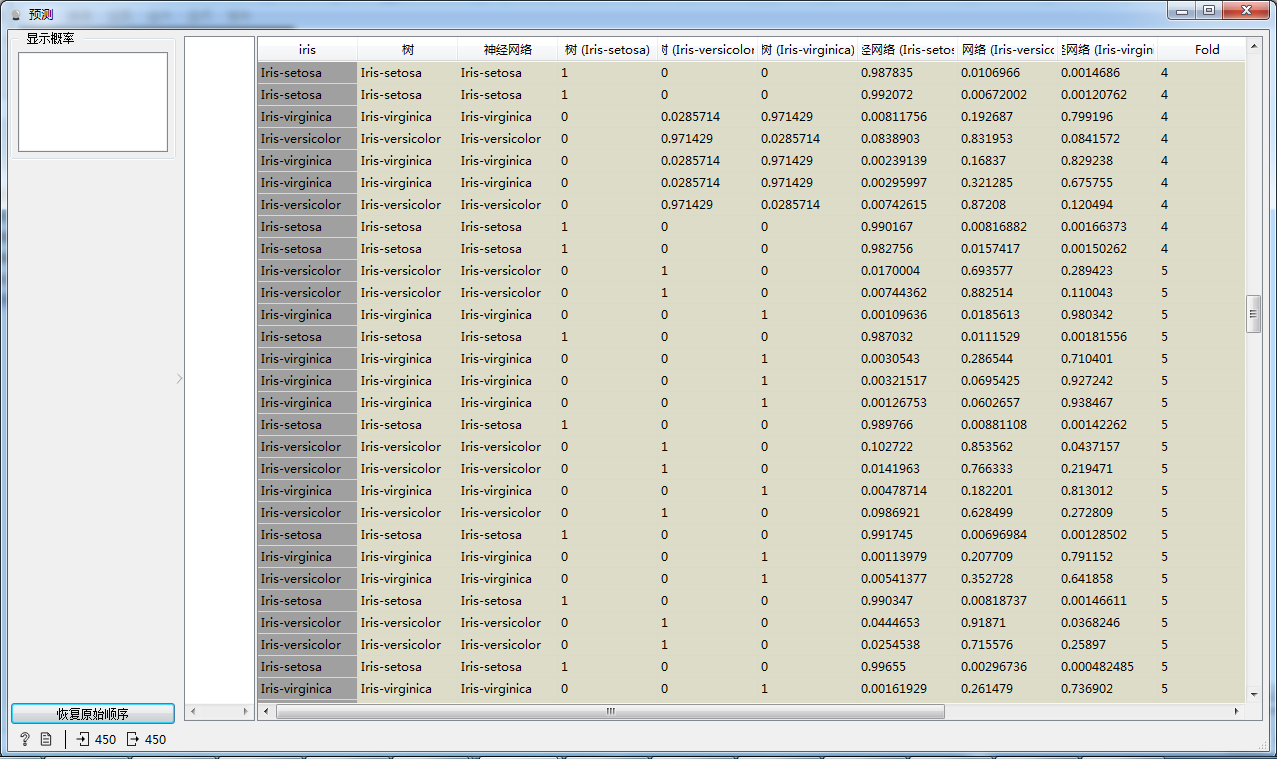
图5
三、结论
本案例构建了以神经网络与决策树算法为基础的鸢尾花(iris)的分类预测模型,由于数据体量较小,采用“10折交叉检验法”进行模型训练,通过比较两种不同预测模型的各种参数性能可以发现,神经网络模型相较决策树模型具有较好的泛化性能,然而模型训练时间成本较高,预测准确度、精度及调和平均值皆逊于决策树模型。