
鸢尾花品种聚类分析
2020-10-06
本案例进一步采用鸢尾花数据集(iris),通过聚类分析对不同品种的鸢尾花进行区分。由于聚类分析属于无监督学习的范畴,数据中不应当存在目标变量,可通过“特征选择”组件将其过滤,聚类算法选用经典的k均值算法进行模型训练,为了观测聚类效果,引入箱线图与散点图等可视化组件,整体的工作流如图1所示。、
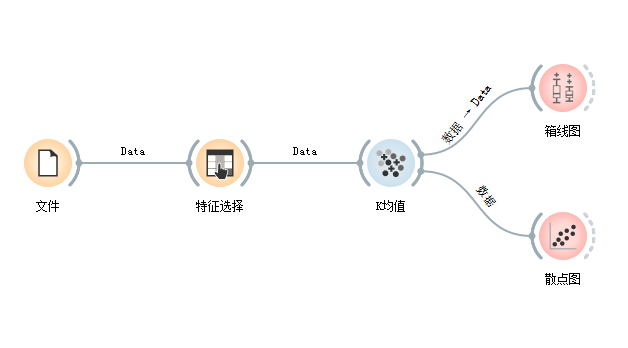
图1
一、案例背景
在鸢尾花的分类预测的案例中,我们根据已知品种的鸢尾花测量数据,对新鸢尾花的品种进行了预测,在本案例中,我们要对一组未知品种的鸢尾花测量数据进行聚类分析,从而将不同品种的鸢尾花区分开。与分类预测不同,聚类算法是一种无监督学习的算法。
二、分析过程
1.数据的导入与观测
添加“文件”组件用于加载本地数据,选择蓝鲸已经集成的iris.tab,即鸢尾花数据集,这是机器学习和统计学中一个经典的数据集。“文件”组件也可以显示数据集的基本信息。
2.特征选择
通过“特征选择”来实现特征过滤,组件设置如图3所示。
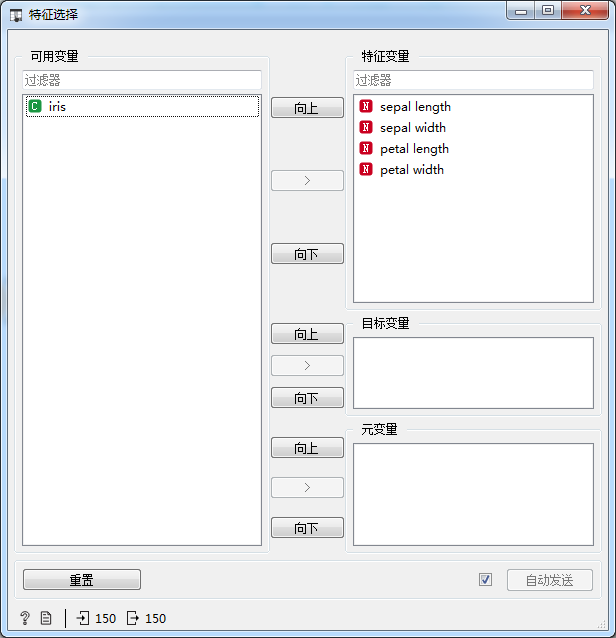
图2
3.算法设置
K均值算法在训练模型时需要指定聚类簇的数量,组件的设置如图4所示。
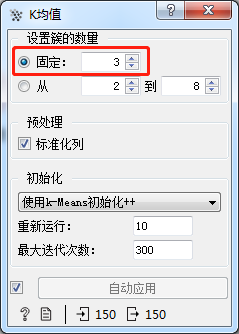
图3
4. 聚类模型的可视化(基于箱线图)
待模型训练完毕,我们可以采用可视化的方式更直观地观测聚类模型的性能。从统计学的角度,我们希望聚类模型中,组内间距尽可能小,组间的间距尽可能大,箱线图可以从量化数据的角度实现定量的描述,如图5所示。

图4
5.聚类模型的可视化(基于散点图)
散点图可以从空间分布的角度更直观地观测聚类模型的分布状态,“散点图”组件的设置和可视化结果如图6所示。
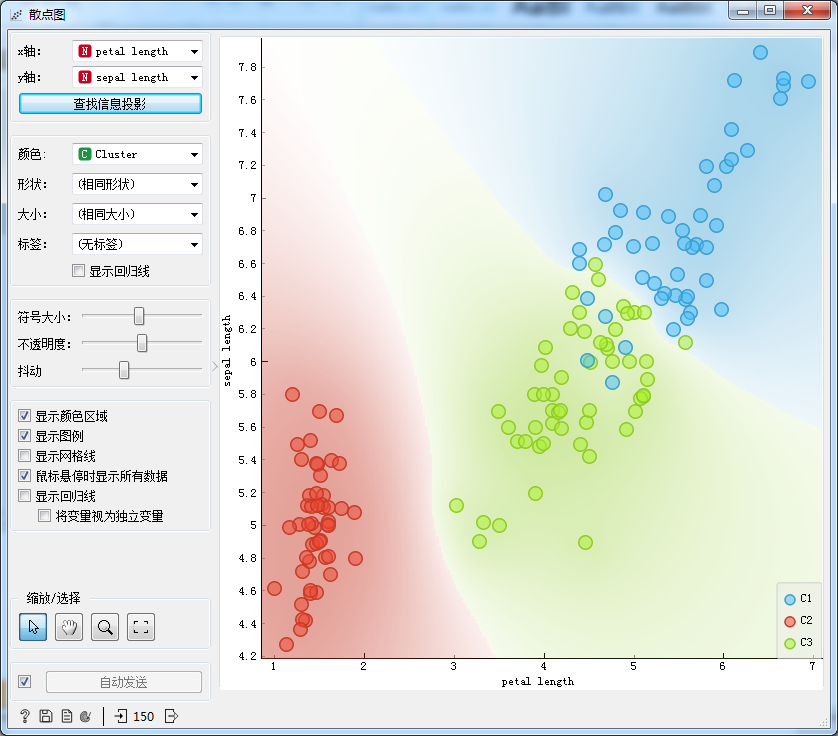
图5
三、结论
在本案例中构建了以k均值聚类算法为基础的鸢尾花(iris)的聚类模型,簇的数量设置为3,较好地实现将不同品种的鸢尾花区分开,第二类品种的鸢尾花在花瓣长度和花萼长度普遍较长,第一类品种的鸢尾花居中,第三类品种的鸢尾花普遍较短。